The role of data science and text mining in the search for new therapies

Today, most drug discovery programmes begin with the identification and validation of disease modifying biological targets. The primary way to uncover these targets is through searching and reviewing published scientific literature. Eric Gilbert explores how data science techniques like text mining are speeding up research into areas such as pancreatic cancer.
The increasing rate of scientific publishing – only made more apparent in 2020 with the flood of important and necessary COVID-19 research – has made the task of sifting through literature extremely difficult and time consuming.
Between just February and May 2020, submissions to Elsevier’s journals alone went up by 58% compared to the same period in 2019. As a result, many researchers and organisations are relying more on digital technologies and data science techniques to help break down and digest the information available. Within this area, text mining is of particular interest because it enables researchers to retrieve highly specified information from unstructured content – which means they can more quickly find meaningful answers to complex research questions.
Text mining can aid the search for new and innovative therapies for many unmet needs where there are large volumes of published literature – for example, oncology. Pancreatic cancer is the third leading cause of cancer death in the United States and the five-year survival rate differs dramatically depending on the stage of the cancer at diagnosis. As such, it is a disease where we urgently need new and innovative therapies to not only treat the cancer but to improve early diagnosis rates.
To explore how data science techniques like text mining can accelerate research into an area like pancreatic cancer, Elsevier developed a new research report using text mining to identify the emerging trends in pancreatic cancer literature over the last two years. The analysis has uncovered a number of research trends and points towards potential new research areas for the development of therapeutics.
Understanding more about the disease and what determines poor patient outcomes
The results of the text mining report bring light to recently trending protein and genomic terms with a semantic relationship to pancreatic cancer, showing the emergence in research in both X-inactive specific transcript (XIST) and lincoo511 (fig.1.). These are both long non-coding RNAs, which have attracted attention in the past two years due to their involvement in several cancers including pancreatic. They have the potential to be not only diagnostic/prognostic biomarkers but also targets of pharmaceutical intervention.
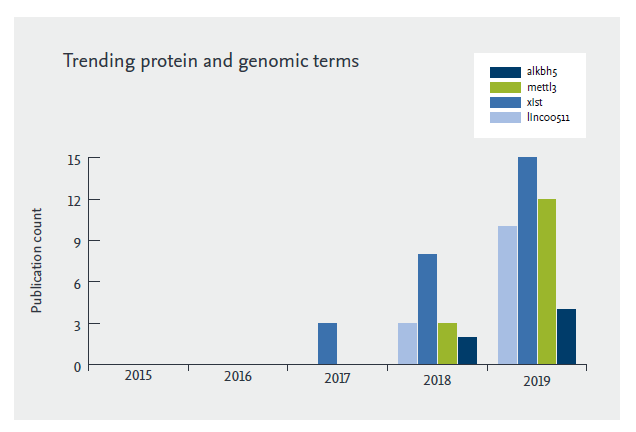
Figure 1: Trending Protein and Genomic terms with a semantic relationship to pancreatic cancer
Text mining was also able to highlight new insights into the mechanisms of pancreatic cancer’s immune evasion, which refers to cancer cells’ ability to evade an immune response. Currently, while progress has been made with the discovery of checkpoint inhibitors, clinical results for immune monotherapies have been disappointing for pancreatic cancer. This is in part due to the immunosuppressive nature of the tumours, however, recent revelations in the mechanism of immune evasion could provide disease-modifying therapeutic targets.
Potential areas for further research
Within the analysis of trending terms, ‘ferroptosis’ was also highlighted in relation to biological functions. The induction of ferroptosis, a type of regulated cell death, is being looked at as a new strategy for pancreatic cancer treatment. This was only discovered in 2012 and is a currently active area of research within pancreatic cancer.
Finally, there is increasing evidence that propofol has biological effects that may alter the progression of pancreatic cancer. Propofol has been used for more than 30 years as an anaesthetic during medical procedures; more recently it has been found to interact with non-coding RNAs and to modulate immune function and a number of signaling pathways. Furthermore, propofol has been shown to suppress autophagy and enhance the activation of T helper cells. While propofol is unlikely to be used therapeutically, it is helping our understanding of pancreatic cancer and cancer in general.
How data science and analysis of research can progress future innovations
We have seen data science techniques applied to many other industries to accelerate innovation and find faster answers. For example, in financial services to help sift through regulatory reports and company filings; in retail to identify trends and analyse consumer decision making; and in entertainment to analyse customer preferences and to make recommendations. Life sciences is considerably more complex, but it can follow suit to help researchers stay current with the ever-expanding scientific literature. It is essential to help equip the R&D sector with a greater depth of information to help battle diseases and tackle unmet needs.
With COVID-19 still impacting the capacity of laboratories, being able to maximise the knowledge in already existing research is more important than ever. It also prevents work being duplicated and empowers future R&D decisions. In terms of pancreatic cancer, current research trends show hope for the development of new treatments and diagnostics. Ferroptosis and immune evasion are highly relevant to pancreatic cancer and remain areas where further research is required. Data science techniques, including text mining, will have an important role to play in further breakthroughs.
About the author
Eric Gilbert is a life sciences consultant at Elsevier. He is an accomplished medicinal chemistry research scientist with over 15 years of experience in drug discovery at Pfizer, Schering-Plough, and Merck. He is author or coauthor of 16 publications and an inventor for 22 issued US patents. Eric possesses a unique combination of synthesis and drug discovery experience along with an extensive data science skill set.










