Tech & Trials: Biostats and medical writing

There are many outputs produced during a clinical trial, and one of the most crucial is the Clinical Study Report (CSR). It details the results, methodology, and analysis of the trial, providing regulators with a transparent look into the safety, efficacy, and methodology of the trial. It also becomes a foundation for future research.
Beyond these technical details, the CSR also outlines the study design (protocol), the motivation for doing it in the first place, and even ethical considerations. Which is all to say, the CSR is like the encyclopedia of the trial.

A crucial piece of the CSR is the “Tables, Listings and Figures” (TLF) section. The TLFs offer narrative, visual, and tabulated representations of the study’s key results, such as the composition of the population, the safety of the treatment, and how effective it was. Producing a TLF is an interplay between the biostatisticians who compute the results and the medical writers who then describe them. Interestingly, sections of the TLF usually follow the guidelines from ICH (the “ICH E3” guidelines) on what data to present and how to present it. Given that there is a structure to the output, but a need for human-level readability, it’s a perfect place for AI to help!
TLF generation
We’ve already discussed how AI can help clean and curate data, so, generating parts of the TLF using that data is the next natural step.
Manually producing the TLF involves an interplay of biostatisticians, terminology coders, statistical programmers, and medical writers. And one successful approach is to apply AI in the same methodology – just, rather than having the humans pass along their output at each step, an AI focused on that specific step will be deployed instead.
Consider the following workflow for writing the Baseline Characteristics section of the TLF. The Baseline section outlines the demographics of the participants, by cohort (e.g., treatment group). It describes the average age, sex, race/ethnicity, and other vitals, such as perhaps their BMI or cancer stages. It’s important because a trial wants these groups to look as similar as possible to each other to minimise potential for bias. Hence it’s importance in the TLF (and CSR overall).
With humans, generating this section starts with biostatisticians determining how to run the statistics for each variable (as outlined in the Statistical Analysis Plan). For instance, age or BMI is a number and the most common way to compute statistics on numbers is to look at mean, standard deviation, median, etc. This contrasts with Cancer staging or Sex, which are categorical (e.g., you pick on of a set of values per patient), in which case the statistics are counts and relative percentages.
After computing the statistics for each group for each variable, the biostatistician would then compare them. This comparison is done using statistical significance testing and, again, the right statistical test is determined by factors such as whether the data is numeric or categorical, how many cohorts you are comparing, and how many “observations” there are (e.g., patient data points). For instance, if you have numeric data and more than two cohorts, you generally run an ANOVA test; while if you have 2 cohorts to compare, you generally do a T-test.
The output of this determination is the right statistical test to run, which is then computed. If the p-value is statistically significant, it means the cohorts were more different from one another, for that field, than we would expect just by chance, a majority of the time (a p-value of 5% means that we only expect their differences to be explained by random chance 5% of the time – so, it's highly likely, around 95%, that the differences are caused by something other than randomness).
The statistical results are then shared with the medical writer, who creates a compelling narrative describing them, and creates tables to show the results. The medical writer then passes the narrative, table, etc., back to the statisticians to ensure that the results are correctly reflected. Once everyone agrees, that part of the TLF is done!

However, we can approach this task in a similar way, using AI.
Some of the TLF components are rote enough that the machine can do them by itself, from statistics to writing. Examples would be analysing safety outputs and describing the population’s baseline characteristics (efficacy is not as good for an AI, as it’s quite bespoke and dependent on the trial).
The first thing the AI will do is to determine the right statistics, given the data and parameters about the data. One way to accomplish this is using an “Expert System”, which is just another term for a decision tree. By looking at statistics textbooks, an AI can create a decision tree that can then be validated by statisticians.
The decision tree would first automatically assess the type of data, such as whether it’s numeric or categorical. Given the type of data, next it would take the parameters (e.g., number of observations, cohorts, etc.) and go down the decision tree until it reaches the final decision of what statistical tests and descriptive statistics to run. After that, the system will compute those exact statistics and then send them to an AI writer (such as a Large Language Model), which would write up the narrative highlighting the statistics. Finally, the AI should compare the written narrative to the supplied statistics, to “fact check” that the writing mirrors the statistics correctly. This exactly follows the human process, but is automated at each step.

In fact, this is precisely how we do it at ReadoutAI. The output for a simple baseline characteristics report can be seen below. Of course, the results must be validated (they have been), but the savings are enormous – moving the process to around 30 seconds.
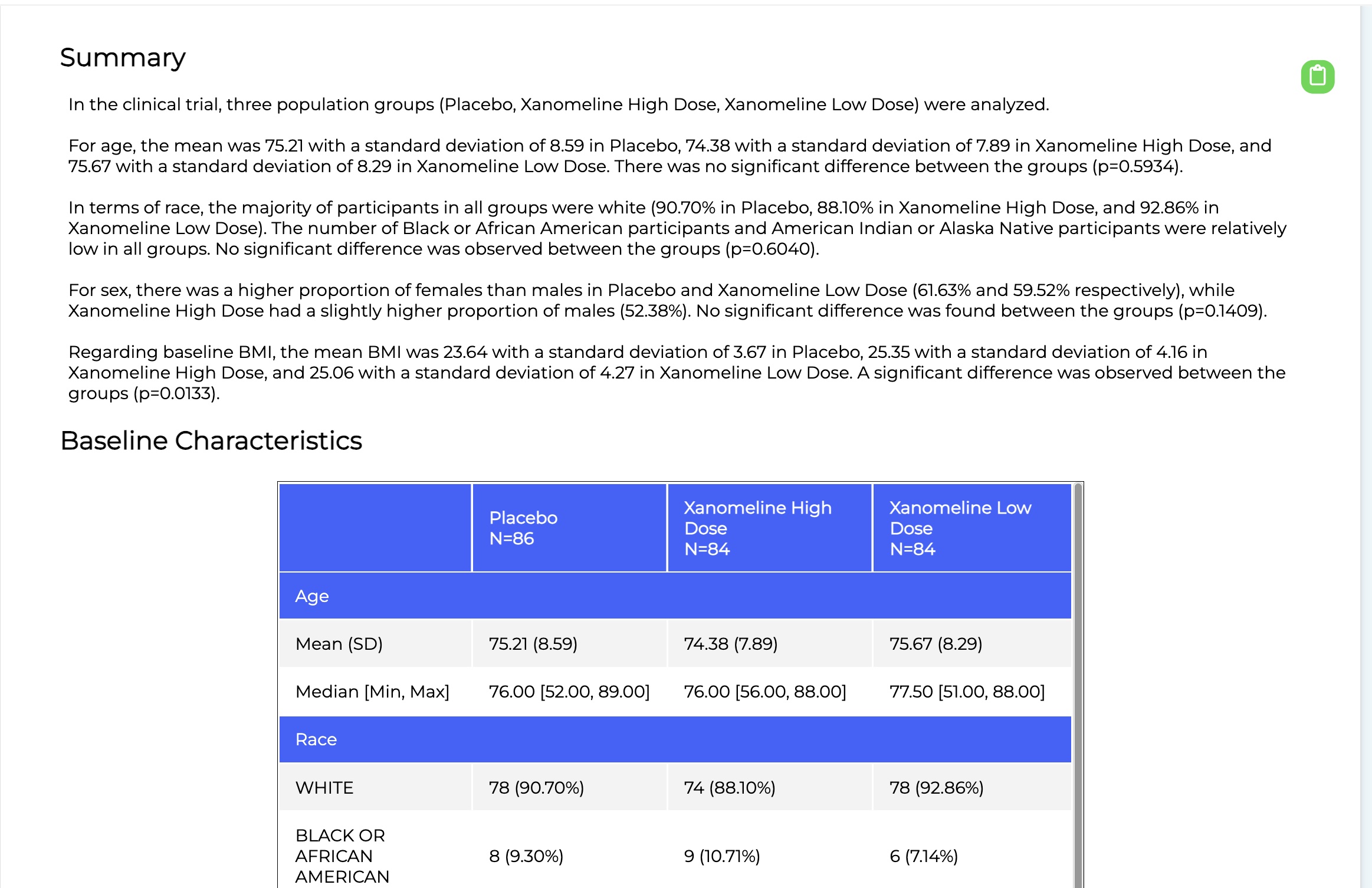
A crucial point is that automation like this supports the rote tasks. The goal is to free the humans to work on the deep, bespoke tasks, such as efficacy analysis, which can vary trial by trial. By leveraging AI, trial times can be shorted as tasks such as TLF generation can offload the more tedious components to an AI, while the humans do the rest.

This is yet another example of how AI can assist humans in some of the more rote tasks in clinical trials, even as those tasks become more sophisticated.
About the author
 Dr Matthew Michelson is an AI-scientist and a serial entrepreneur. He is currently the CEO of ReadoutAI, a company that automates clinical trial data analysis and insights by integrating AI deeply into data management, biostatistics, and medical writing. He previously co-founded Evid Science, an AI literature analysis company, which was acquired by Genesis Research, a real-world evidence technology and service company, where he also served as president. Genesis Research was subsequently acquired as well. Michelson has published nearly 40 peer-reviewed papers in AI and machine learning, many at the intersection of AI and healthcare. He received his BSc from Johns Hopkins University and his PhD from the University of Southern California, all in Computer Science.
Dr Matthew Michelson is an AI-scientist and a serial entrepreneur. He is currently the CEO of ReadoutAI, a company that automates clinical trial data analysis and insights by integrating AI deeply into data management, biostatistics, and medical writing. He previously co-founded Evid Science, an AI literature analysis company, which was acquired by Genesis Research, a real-world evidence technology and service company, where he also served as president. Genesis Research was subsequently acquired as well. Michelson has published nearly 40 peer-reviewed papers in AI and machine learning, many at the intersection of AI and healthcare. He received his BSc from Johns Hopkins University and his PhD from the University of Southern California, all in Computer Science.










